
R Markdownでデータ分析の結果を即座に文書化できます。この記事を読むと、以下の文書出力ができるようになります。
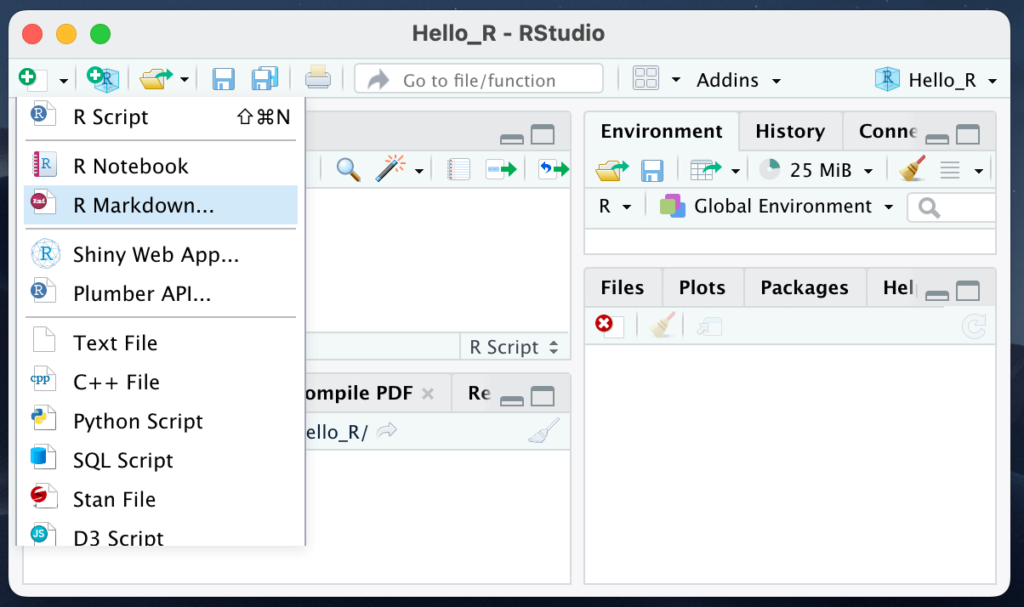
まず、準備のためにコード1を実行してください。PCごとに1回実行すればOKです。
#コード1
#パッケージrmarkdownのインストール
install.packages('rmarkdown')
#パッケージrmarkdownの呼び出し
library(rmarkdown)
#パッケージtinytexのインストール
install.packages('tinytex')
#TinyTexをインストール ※LaTeXが使えるようになります
tinytex::install_tinytex()
# IPAフォントをインストール ※日本語が使えるようになります
tinytex::tlmgr_install("ipaex")左上の+からR Markdownを起動します。Title(タイトル)やAuthor(著者)を適当に入力し、「HTML」ではなく「PDF」にチェックをいれましょう。
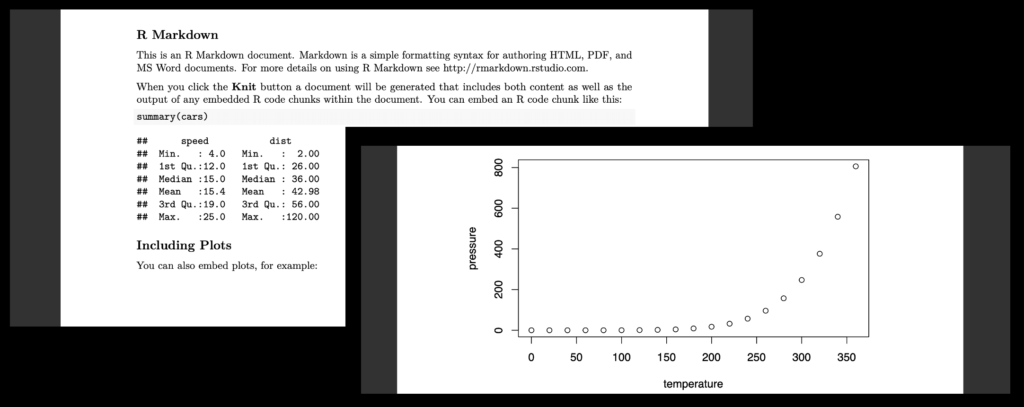
「Knit(ニット)」を押すと、PDF化の作業に入れます。初期文書をニットすると、次のPDFが出力されます。
日本語フォントを使用可能とするために、次のコードを冒頭にコピペしてください。
---
title: "タイトル"
author: "著者"
output:
pdf_document:
latex_engine: xelatex
header-includes:
- \XeTeXlinebreaklocale "ja"
- \XeTeXlinebreakskip=0pt plus 1pt
- \XeTeXlinebreakpenalty=0
mainfont: ipaexm.ttf
---冒頭のコードはyamlヘッダと言います。コードの意味は以下の通りです。
output: #出力形式
pdf_document: #PDFで出力
latex_engine: xelatex #LaTeXの中のxelatexを使う
header-includes: #日本語でも自動折り返しできるようにする
- \XeTeXlinebreaklocale "ja"
- \XeTeXlinebreakskip=0pt plus 1pt
- \XeTeXlinebreakpenalty=0
mainfont: ipaexm.ttf #明朝体指定(フォントによっては自動折り返しできない)次の文章をコピペして、ニットしましょう。日本語のPDFが出力されます。
---
title: "タイトル"
author: "著者"
output:
pdf_document:
latex_engine: xelatex
header-includes:
- \XeTeXlinebreaklocale "ja"
- \XeTeXlinebreakskip=0pt plus 1pt
- \XeTeXlinebreakpenalty=0
mainfont: ipaexm.ttf
---
# 第1章 基本文法
## 1節 見出し
「#」「##」で見出しを作成できる。「#」の直前に文字やスペースがあると、見出しが作れない。
## 失敗した見出しの例
## 2節 改行
改行は半角のスペースを2個続けると→
できます。
## 3節 数式
数式はドルマーク2つで挟んでください。LaTeXでの数式表現が使えます。$e = mc^2$
## 4節 コメント
下のコードを打つことで、コメントを挿入できます。
<!--
コメントです。コードだと見えます。
-->
↑PDFでは上のコードは見えません。
## 5節 脚注
R Markdownにも脚注[^1]をつける方法がある。脚注はそのページ下部に小さく記される。
\[^1] 脚注とは、本文の下部に載せる補足情報。意味、解釈、出典が記される。
# 第2章 Rコードを反映させる
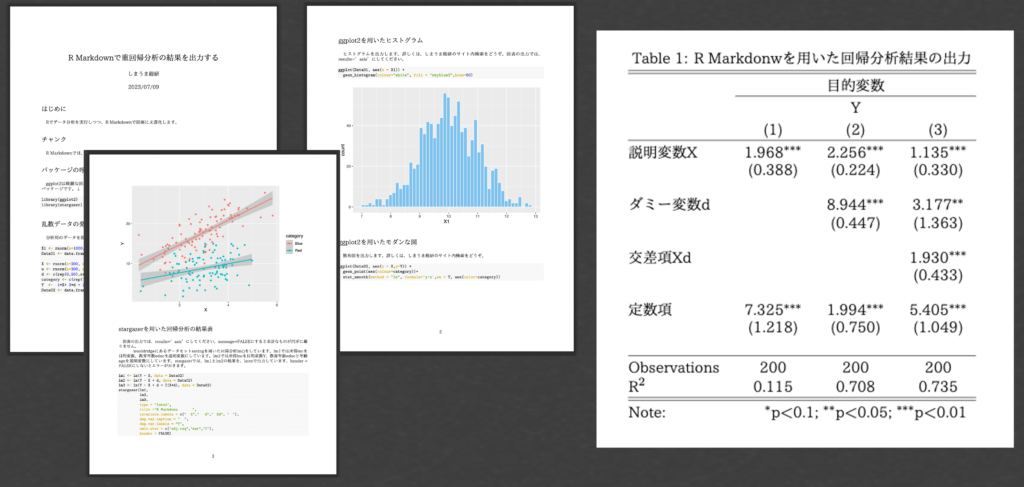
データ分析結果も出力しましょう。
---
title: "R Markdownで重回帰分析の結果を出力する"
author: "しまうま総研"
date: "`r format(Sys.time(), '%Y/%m/%d')`"
output:
pdf_document:
latex_engine: xelatex
header-includes:
- \XeTeXlinebreaklocale "ja"
- \XeTeXlinebreakskip=0pt plus 1pt
- \XeTeXlinebreakpenalty=0
mainfont: ipaexm.ttf
---
# はじめに
Rでデータ分析を実行しつつ、R Markdownで即座に文書化します。
# チャンク
R Markdownでは、チャンクにてRコードを走らせます。チャンクは「```{r} ```」で囲まれた部分です。
# パッケージの呼び出し
ggplot2は綺麗な図表を作ってくれるパッケージ、stargazerは回帰分析の結果を綺麗にまとめてくれるバッケージです。↓
```{r , message=FALSE}
library(ggplot2)
library(stargazer)
```
# 乱数データの発生
分析用のデータを乱数発生させています。
```{r, results='asis', message=FALSE}
X1 <- rnorm(n=1000, mean =10, sd=1)
Data01 <- data.frame(X1)
X <- rnorm(n=200, mean =3, sd=1)
u <- rnorm(n=200, mean =0, sd=3)
d <- c(rep(0,50),rep(1,50))
category <- c(rep("Red",50),rep("Blue",50))
Y <- 1*X+ 3*d + 2*d*X+ 6 + u
Data02 <- data.frame(X,Y,d,category)
```
# ggplot2を用いたヒストグラム
ヒストグラムを出力します。詳しくは、しまうま総研のサイト内検索をどうぞ。図表の出力では、results='asis'にしてください。
```{r, results='asis', message=FALSE}
ggplot(Data01, aes(x = X1)) +
geom_histogram(colour="white", fill = "skyblue2",bins=50)
```
# ggplot2を用いたモダンな図
散布図を出力します。詳しくは、しまうま総研のサイト内検索をどうぞ。
```{r, results='asis', message=FALSE}
ggplot(Data02, aes(x = X,y=Y)) +
geom_point(aes(colour=category))+
stat_smooth(method = "lm", formula='y~x',se = T, aes(color=category))
```
# stargazerを用いた回帰分析の結果表
図表の出力では、results='asis'にしてください。message=FALSEにすると余計なものがPDFに載りません。
wooldridgeにあるデータセットsavingを用いた回帰分析lm()をしています。lm1では所得incを目的変数、教育年数educを説明変数にしています。lm2では所得incを目的変数Y、教育年数educと年齢ageを説明変数にしています。stargazerでは、lm1とlm2の結果を、latexで出力しています。header = FALSEにしないとエラーがおきます。
```{r, results='asis', message=FALSE}
lm1 <- lm(Y ~ X, data = Data02)
lm2 <- lm(Y ~ X + d, data = Data02)
lm3 <- lm(Y ~ X + d + I(X*d), data = Data02)
stargazer(lm1,
lm2,
lm3,
type = "latex",
title ="R Markdonwを用いた回帰分析結果の出力",
covariate.labels = c("説明変数X","ダミー変数d","交差項Xd", "定数項"),
dep.var.caption = "目的変数",
dep.var.labels = "Y",
omit.stat = c("adj.rsq","ser","f"),
header = FALSE)
```