
インストールと呼び出し
重回帰分析の推定結果を綺麗に出力するstargazerのパッケージをインストールして、読み込みます。
# パッケージのインストール(初回のみ)
install.packages("stargazer")
# パッケージの呼び出し
library(stargazer)
準備:回帰分析をする
同じ出力を再現できるように次のコードを実行してください。
# 回帰分析をする
install.packages("wooldridge")
library(wooldridge)
MLR1 <- lm(wage ~ educ + IQ, data=wage2)
text形式での出力
# 回帰分析MLR1の結果を、text形式で出力
stargazer(MLR1, type="text")
カスタマイズ
stargazer(MLR1, #回帰分析の名前。"MLR1,MLR2,MLR3"と並べると、複数の結果を比較で得切る。
type = "latex", #出力形式。text、latex、htmlが選べる。R Markdownで出力場合はlatexし、チャンクの中にresults='asis'をいれてください。
title = "", #表のタイトル
out = NULL, #htmlで出力する場合は"name.html"のように名前を入れる
covariate.labels = NULL, #説明変数の名前を変える c("Years of education","IQ","Intercept")のように書く
dep.var.caption = NULL, #Dependent variableの部分を変えられる
dep.var.labels = NULL, #Dependent variableの下のwageを変えられる
ci = FALSE, #TRUEにすると標準誤差ではなく信頼区間を出力する
ci.level = 0.95, #95%信頼区間
intercept.bottom = TRUE, #TRUEにすると定数項が一番下に来ます
intercept.top = FALSE, #TRUEにすると定数項が一番上に来ます
notes = NULL, #表の下のnoteに文章を付け加えられます
omit.stat = NULL #統計量を省けます。n=サンプル・サイズ、rsq=決定係数、adj.rsq=自由度調整済み決定係数、ser =残差の標準誤差、f=f統計量
)例↓
stargazer(MLR1,
type = "html",
title = "TITLE",
out = "mlr.html",
covariate.labels = c("Years of education","IQ","Intercept"),
dep.var.caption = "Outcome variable",
dep.var.labels = "wage(dollars)",
omit.stat = c("adj.rsq","ser","f") )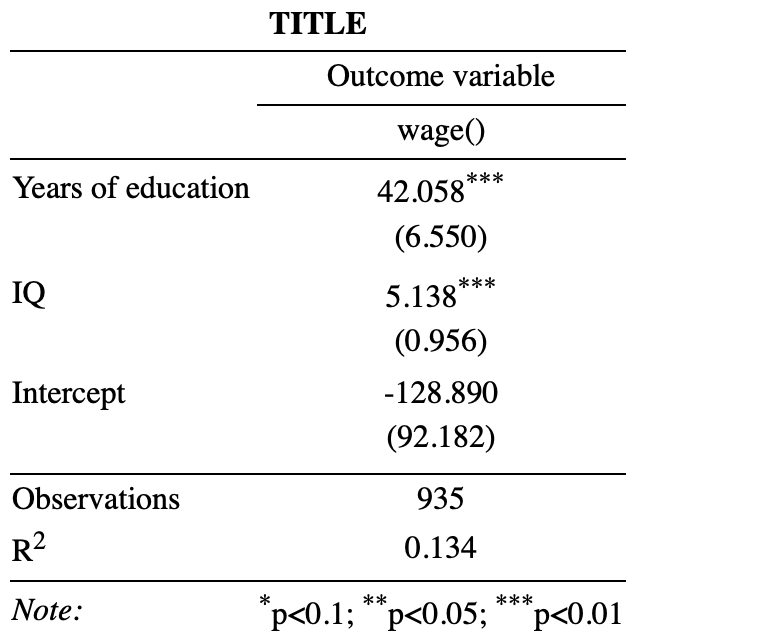
日本語化
上のカスタマイズで、日本語を打つとバグる場合が多いです。日本語入力をしたい場合のおすすめは、(1)日本語入力ができるように調整されたR Markdown上に出力するか、(2)英語のままlatexコードで出力しlatex編集ソフト上で日本語化することです。(2)で編集した例が下です。

\begin{table}[!htbp] \centering
\caption{推定結果}
\label{}
\begin{tabular}{@{\extracolsep{5pt}}lc}
\\[-1.8ex]\hline
\hline \\[-1.8ex]
& \multicolumn{1}{c}{目的変数} \\
\cline{2-2}
\\[-1.8ex] & 賃金 \\
\hline \\[-1.8ex]
教育年数 & 42.058$^{***}$ \\
& (6.550) \\
& \\
知能指数 & 5.138$^{***}$ \\
& (0.956) \\
& \\
定数項 & $-$128.890 \\
& (92.182) \\
& \\
\hline \\[-1.8ex]
サンプル・サイズ & 935 \\
決定係数 & 0.134 \\
\hline
\hline \\[-1.8ex]
\textit{メモ:} & \multicolumn{1}{r}{$^{*}$p$<$0.1; $^{**}$p$<$0.05; $^{***}$p$<$0.01} \\
\end{tabular}
\end{table}