
標準誤差とは、推定量の標準偏差の推定値だ。標準誤差とは、推定量のバラツキを意味する。標準誤差は、複数の概念が入れ子構造になっており、意味がわかりにくい。数式で表現すると、下のようになる。
$$SE= \widehat{SD \left( \widehat{\theta} \right)}$$
$$SE:標準誤差、SD:標準偏差$$
$$\theta:母集団におけるパラメーター(定数)$$
$$\widehat{ \theta } :標本から計算できる \theta の推定量(確率変数)$$
慶應義塾大生の身長平均を求める場合で、標準誤差を考えよう。慶應義塾大生2.9万人の身長データを擬似的に生成した(図1)。慶應義塾大生の平均は、166.14cmであった。つまり、母集団たる全慶應義塾大生の、母平均というパラメーターθは、166.14である。ここで慶應生をランダムに100人連れてきて、標本平均を取るのを1万回繰り返し、標本平均を計算した(図2)。つまり、パラーメーターの推定値^θを1万個得た。得られる標本は毎回異なるので、当然推定値にもバラツキが生じる。このバラツキの標準偏差(SD, standard deviation)は0.83だった。SD(^θ)=0.83だ(ということにしよう)。標本平均を1回取った際にこの0.83を推定するのが、標準誤差(SE, standard error)である。標準誤差は1回の標本抽出だけで、推定量のバラツキを推定してしまおうという野心的な概念だ。
$$標準誤差SE= \widehat{SD \left( \widehat{\theta} \right)}$$
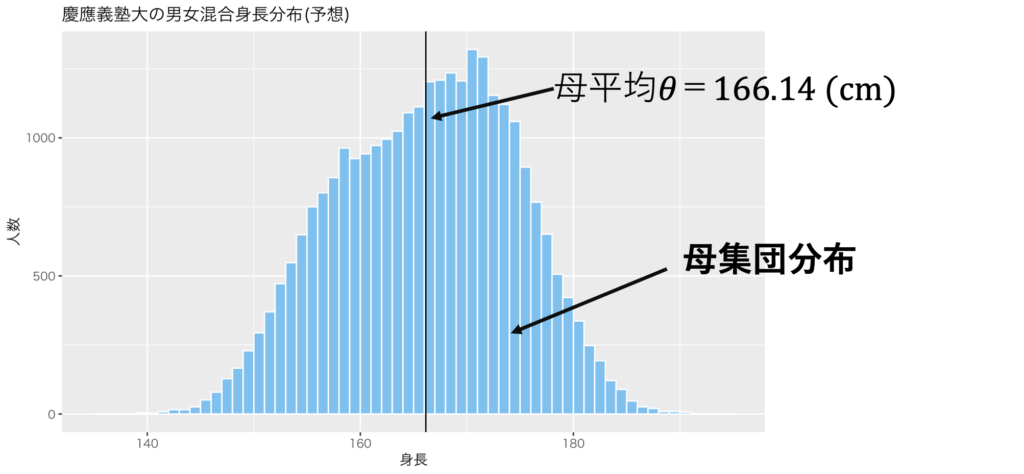
出典:しまうま総研(2023)
解説:コードは付録に掲載
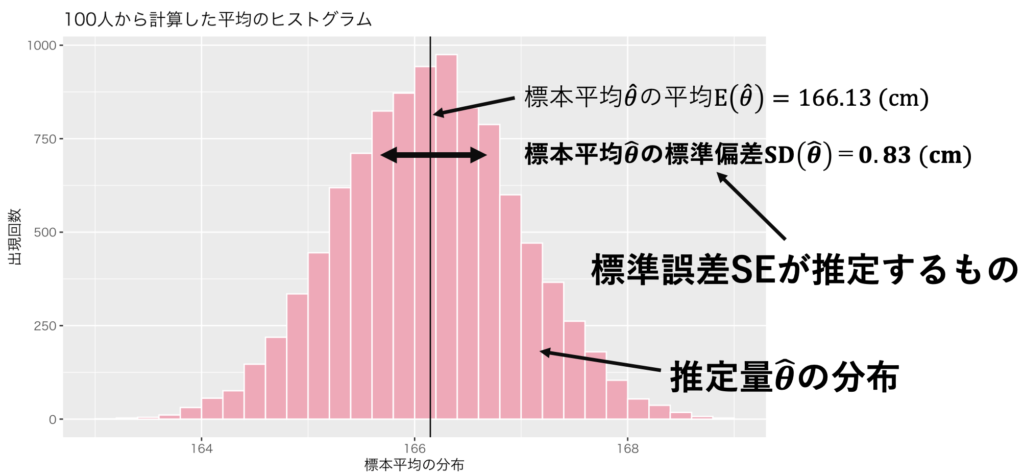
出典:しまうま総研(2023)
解説:コードは付録に掲載
標準誤差がわかりにくいのは、原理的な理解が求められること、名称の混同が起きやすいこと、その目的が不明瞭なことに起因する。原理的な理解として「母集団と標本、パラメーターと推定量」という統計的推論の考えができてなければならない。そして、標準偏差と標準誤差は1文字しか違わないのに紙面のほぼ同じところに出現する。さらに、標準誤差が何を推定しているのかを読んでもよくわからない文献は意外とある。標準誤差は、推定量の標準偏差を推定している。
【追記】
・慶應生の身長分布の生成方法についてメモしておく。2022年度の慶應生は28,641人で、そのうち63%にあたる18,286人が男子学生である。男女ともに17歳の平均身長、標準偏差の正規分布に従うとして乱数生成した。17歳男子は平均170.8cm、標準偏差5.90である。17歳女子は平均158.0cm、標準偏差5.39である。17歳のデータを用いたのはサンプルサイズが大きく信頼のおける高校のデータであるのと、高3と大学生で体格差はないと考えたからである。
・Rコードは次の通り。
#慶應生の身長を擬似的に生成する
population_size <- 28641
x <- rep(NA, population_size)
for(i in 1:population_size){
x[i] <- ifelse(i < 18286,rnorm(1,170.8,5.90) , rnorm(1,158.0,5.39))
}
data0 <- data.frame(x)
#標本を1万回生成し、標本平均を1万回計算する
trial_number <- 10000
sample_size <-100
mean_0 <- rep(0, trial_number)
for(i in 1:trial_number){
s <- sample(data0$x, sample_size, replace = FALSE) #無作為抽出
mean_0[i] <- mean(s) #平均の計算
}
data00 <- data.frame(mean_0)
#ggplot2によってヒストグラムを作図する
#パッケージの呼び出し。
library(ggplot2)
#母集団の分布
ggplot(data0, aes( x = x )) +
geom_histogram(breaks = c(135:195),colour="white", fill = "skyblue2")+
xlab("身長") +
ylab ("人数") +
geom_vline(xintercept =mean(x) )+
ggtitle ("慶應義塾大の男女混合身長分布(予想)") +
theme_grey(base_family = "HiraKakuPro-W3")
#標本平均の分布
ggplot(data00, aes( x = mean_0)) +
geom_histogram(bins=80,breaks = seq(163, 169, by = 0.2),colour="white", fill = "pink2")+
xlab("標本平均") +
ylab ("出現回数") +
geom_vline(xintercept =mean(x) )+
ggtitle ("100人から計算した平均のヒストグラム") +
theme_grey(base_family = "HiraKakuPro-W3")
#計算
mean(x) #慶應生の身長の母平均
mean(mean_0) #標本平均の平均
sd(mean_0) #標本平均の標準偏差